If you’ve ever seen Google Photos neatly organize your pictures by faces or places, noticed how YouTube seems to know exactly what video you’ll want to watch next, or been amazed at how Uber shows you the fare and estimated time before the ride even begins, you’ve already experienced the power of machine learning in your everyday life. It often feels magical—like the app can read your mind and understand your habits. But the truth is, this “magic” doesn’t come easy. Behind the scenes, developers spend countless hours training machine learning models, and along the way, they run into some tough challenges like handling messy data, avoiding biased predictions, or making sure the model learns just the right amount without getting confused.
-
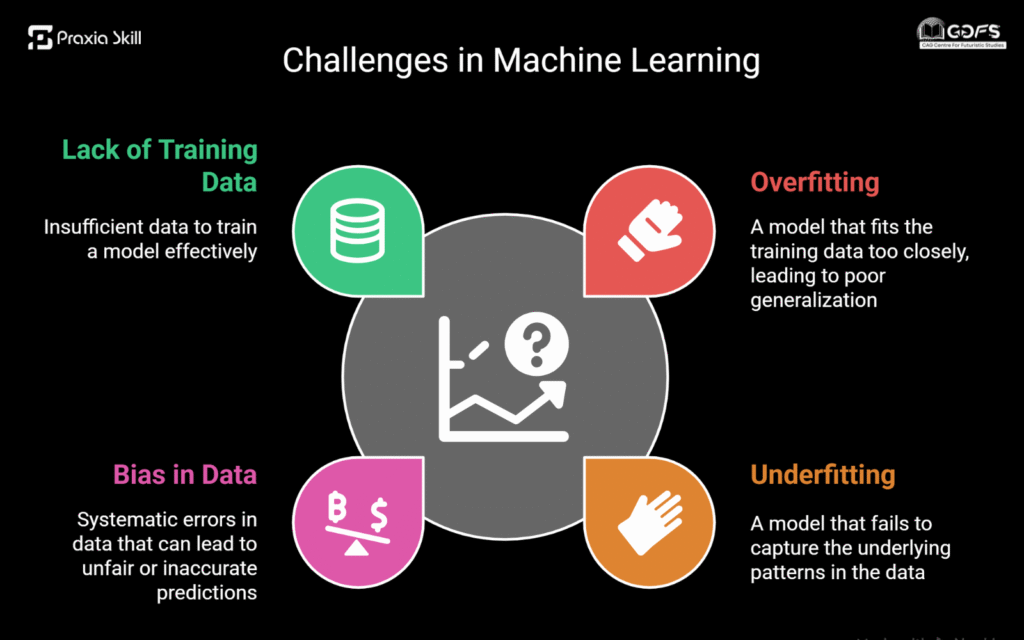
Overfitting and Underfitting Explained Visually
Imagine preparing for an exam:
- Overfitting is like memorizing every single practice question without understanding the concepts. You’ll do great on mock tests but struggle with new, unseen questions.
- Underfitting is the opposite—you barely study, skim a few notes, and end up unprepared for almost everything.
In machine learning, overfitting happens when a model learns the training data too well, including the noise and errors. Underfitting occurs when the model is too simple to capture patterns.
How to fix this?
- Use cross-validation to test your model on different data subsets.
- Apply regularization techniques to prevent models from becoming too complex.
- Choose the right level of complexity—neither too simple nor too detailed.
-
Bias in Data and Its Impact
Have you ever noticed that some voice assistants struggle more with certain accents? That’s a classic case of data bias.
Bias happens when the data used to train the model isn’t diverse enough. For example:
- A job filter trained only on resumes from one demographic might unfairly reject qualified candidates.
- A facial recognition system trained mostly on lighter-skinned faces may perform poorly on darker-skinned individuals.
This is one of the biggest machine learning challenges, as biased data can lead to unfair, inaccurate, or even harmful outcomes.
How to reduce bias?
- Collect diverse and representative datasets.
- Continuously monitor model outputs for unfair patterns.
- Use fairness tools like IBM’s AI Fairness 360 toolkit to detect and address bias.
-
Lack of Enough Training Data
Machine learning models are like students—they need enough examples to learn properly. Without enough quality training data, even the smartest algorithms can struggle.
For instance, if you want an ML model to recognize cats and you only provide 50 cat pictures, it won’t perform well when it sees a new photo.
How to overcome this?
- Use data augmentation (e.g., flipping, rotating, or zooming images) to artificially expand datasets.
- Apply transfer learning, where you take a pre-trained model (like one trained on millions of images) and fine-tune it for your smaller dataset.
- Explore synthetic data generation, where artificial but realistic data is created to fill in the gaps.
-
How to Improve Model Performance
You’ve built your machine learning model, but it’s not quite giving the results you hoped for. So, what can you do? Think of it like coaching a beginner athlete—you try small changes, see what works, and gradually help them perform better.
Simple ways to make your model better:
- Adjust settings (Hyperparameter tuning) – Changing small settings, like how fast the model learns, can make a big difference.
- Improve the input data (Feature engineering) – Picking the right information for the model or creating new useful data often helps more than changing the model itself.
- Try different approaches (Algorithms) – Sometimes switching the type of model—like from a simple decision tree to a neural network—can improve results a lot.
The key is to experiment, test, and improve step by step. Don’t worry about making it perfect on the first try—every small improvement counts!
Conclusion: Don’t Fear the Challenges
At first, machine learning can feel a bit overwhelming, almost like diving into something too complex to handle. But the truth is—it’s just like learning any new skill. There will be bumps along the way, but each challenge is a chance to grow.
Whether it’s figuring out how to stop a model from “overstudying” (overfitting), fixing biased data, dealing with not enough training examples, or simply making your model perform better, there’s always a solution.
And here’s the good news: every time you solve one of these problems, you get better and more confident at ML. So instead of seeing challenges as obstacles, think of them as stepping stones that are helping you move closer to building smarter, fairer, and more helpful AI systems.



){kind=link}
&description=&image=https://blog.praxiaskill.com/wp-content/uploads/2025/08/Untitled-design-32-1024x640.png){kind=link}